How I De-Vibed a Vibe-Coded NLP App
At the start of this year, I vibe-coded a cool Spotify Wrapped style analysis of my prompting patterns, which I called “How I Prompt”. The idea was to apply text analysis / NLP (natural language processing) to my saved AI chat logs and build out a “persona” based on prompting style. It was fun, and catchy, especially showing a “You’re absolutely right!” count, providing easy evidence of the level of AI sycophancy built into the tools. And it took me all but 1 day to build, package and deploy to Github pages.
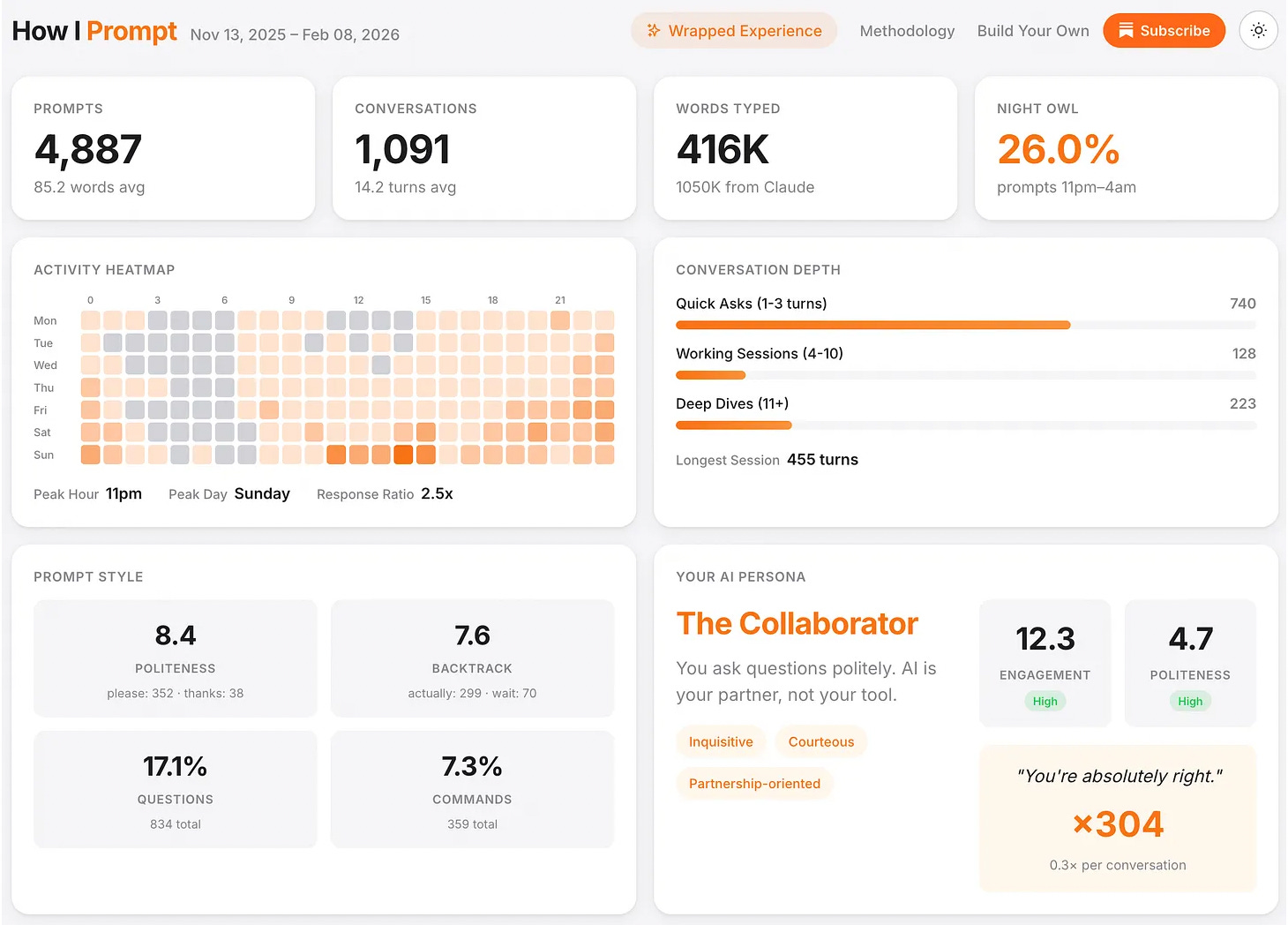
The vibe-coded version was dead simple, with hard-coded regex comparisons on things like question rate, backtrack rate, politeness, command rate. Two axes, which generated four personas using threshold cutoffs. I did check the code even then, but I did absolutely ZERO data-validation or methodology validation.
Literally the job of a data scientist.
The UI looked very nice, the personas and metrics looked quite plausible, I gave in to the confirmation bias that my style was that of a “Collaborator”, and of course the AI was super confident in its work, so I vibed along with it.
But as I’ve been immersing fully into agentic coding, I’ve also been trying to take the contrarian path of not surrendering my critical thinking and decision-making abilities. I wrote about these “effects” of agentic coding in my previous posts The Dopamine Trap of AI Coding and Agentic Coding for Non-Vibe Coders. This was also communicated even more effectively by Mario Zechner (creator of my fav tool — Pi coding agent) — Thoughts on slowing the fuck down. The truth remains — if you want to build anything of substance using AI, you have to slow down, and share the workload.
So in this post, I’m sharing my experience on how I went back to the vibe-coded version and spent some time de-vibing the How I Prompt app.
TLDR;
To fix the AI slop, initially I didn't fully get back into the weeds, and stayed lazy, asking the AI to go "make the app more statistically sound". The AI threw in an embeddings model without validating anything, then when I finally opened the hood, found out that the four "independent" axes were not statistically distinguishable, the data was full of garbage (error logs, CLI noise, subagent prompts all counted as human prompts), and one persona was literally unreachable. The full audit took me a week. I rebuilt it with external research, 21K prompts from public datasets, and two new axes that actually move independently (correlation=0.20 vs the old 0.80). It’s much better now, but if I had to perfect it, I’d rather consult a real domain expert.
Try it for yourself:
npx @eeshans/howiprompt
Failed first attempt: asking AI to fix what AI built
A few weeks later I came back to the project. I wanted to port it from a Python script which Claude built initially to a proper Node.js pipeline to match my Astro frontend, and I thought the underlying analysis engine also deserved an upgrade. The v1 regex approach felt too crude. So I asked Claude to “make it smarter”. That was a vibe-fix of course given the quality of the prompt here.
Claude seemed to actually make a better version, or at least it looked that way. This intermediate version used a sentence embeddings model with cosine similarity. Instead of counting keywords, it generated hundreds of reference examples for each behavioral axis (”refactor the auth module” for Precision, “how does this caching layer work?” for Curiosity), embedded them into vectors, and scored every prompt by how similar it sounded to each axis. I got four axes — Precision, Curiosity, Tenacity, Trust — producing five different personas. It had real ML in it now, and “felt” legit.
But I didn’t release that version. It’s when I finally looked into the proverbial mirror and asked myself if I was just comfortable not looking at the data or the code at all?
The audit
When I finally sat down to check whether the persona system was statistically sound, I had to force myself to bring in a lot more focus, which I wasn’t used to any more having worked with AI agents all the time. Also, if you’re an engineer or data scientist reading this, I’m sure you are very familiar that uncomfortable feeling of inheriting someone else’s code and then trying to understand it and fix it.
So I started investigating along a few different angles, and this is what I found.
The behavioral axes were arbitrary, and not statistically distinguishable.
The first test was simple: are the four axes measuring different things? I looked at how similar the reference examples were across axes. If Precision and Curiosity are different concepts, their reference examples should look different to the model.
They didn’t. They all looked the same.
The model couldn’t tell “debug the auth middleware” (Precision) apart from “explore the auth flow” (Curiosity) because it was seeing the word auth, not the behavioral difference
The AI picked Precision, Curiosity, Tenacity, Trust because they sounded good. Nobody checked whether those concepts are distinguishable in how people write prompts
A general-purpose embedding model can’t distinguish them — it needs more behavioral markers
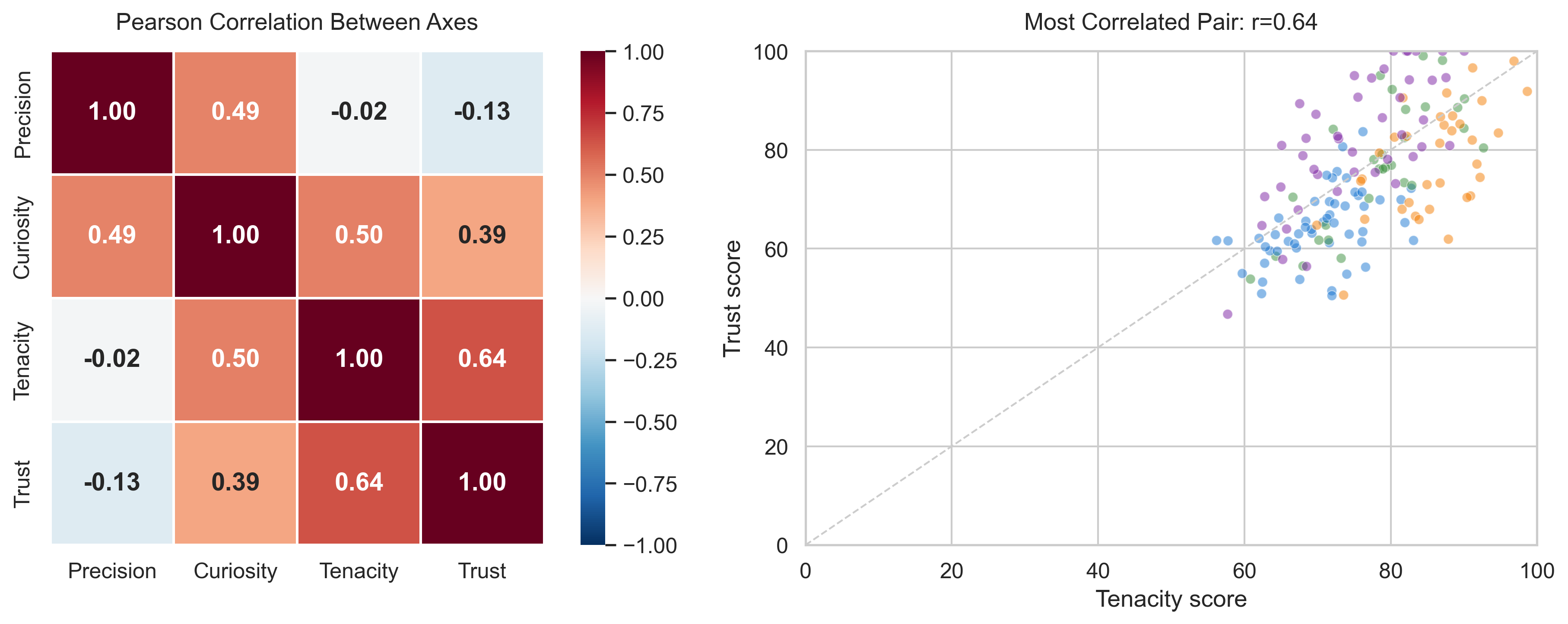
The model was trained on one person.
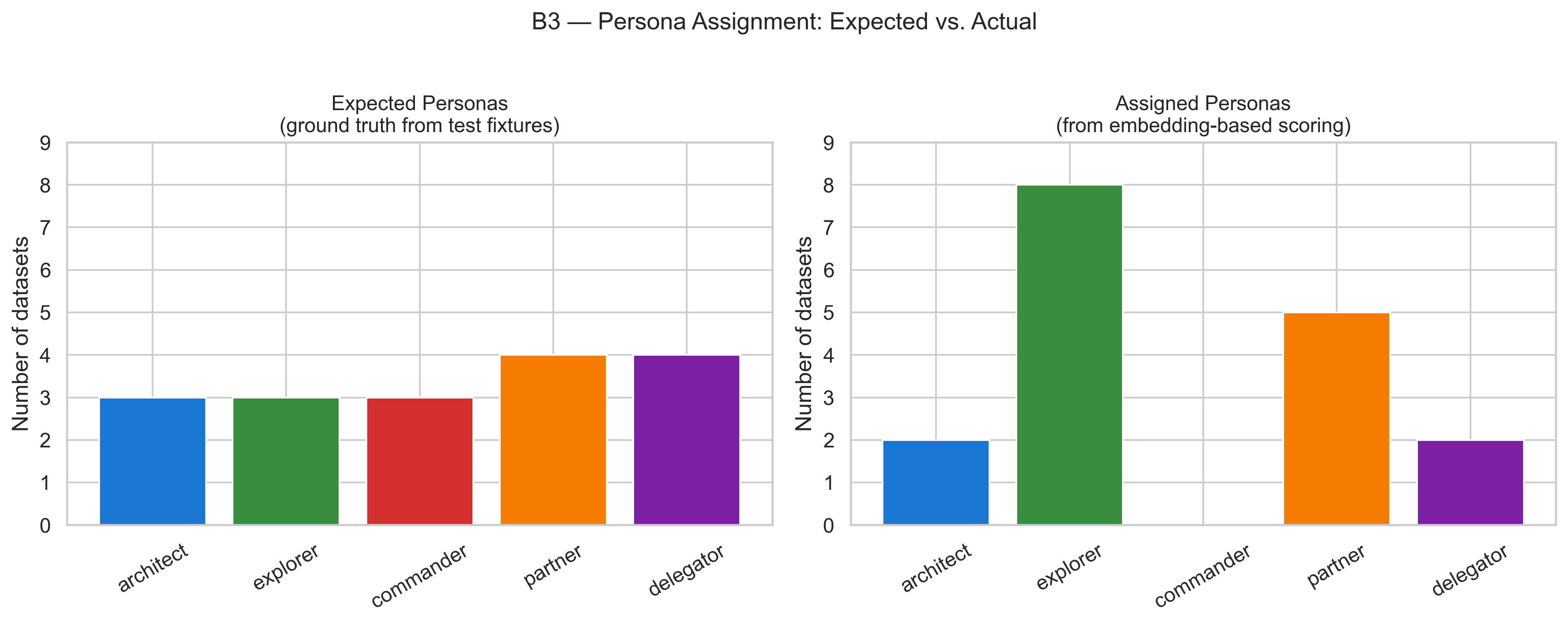
Then I tested whether it could classify anything correctly. I fed in some balanced test data — a few prompts per persona — and checked the outputs.
The classifier assigned eight out of seventeen as Explorer (only one out of the 5 persona types)
It assigned ZERO as Commander. The Commander persona was mathematically unreachable
The Curiosity axis scored everything above 82 out of 100 regardless of what the prompt said
Every reference example, every threshold, every validation, was all based on my conversation data and my unique prompting style. Clustering one person’s prompts tells you about that person’s modes, not about universal patterns. The system was just mirroring my behavior, and of course couldn’t be used as a generalized measurement tool.
The data was bad.
When I had originally built this tool, the only thing I had prompted the AI was to find my conversation data and then build this analysis pipeline. And that’s exactly what it did. Once it found the data, it built something, but there was no validation on if it was actually my conversation data or was it bringing in anything else.
The pipeline was ingesting error logs, framework messages, subagent prompts, CLI noise from
node_modules— all of it counted as “human prompts”The persona classifier was scoring machine-generated boilerplate alongside real conversation
Cleaning this up took longer than any other part of the project. I manually ran a ton of SQL analysis and had to build a rules engine with 39 exclusion rules to filter out the noise
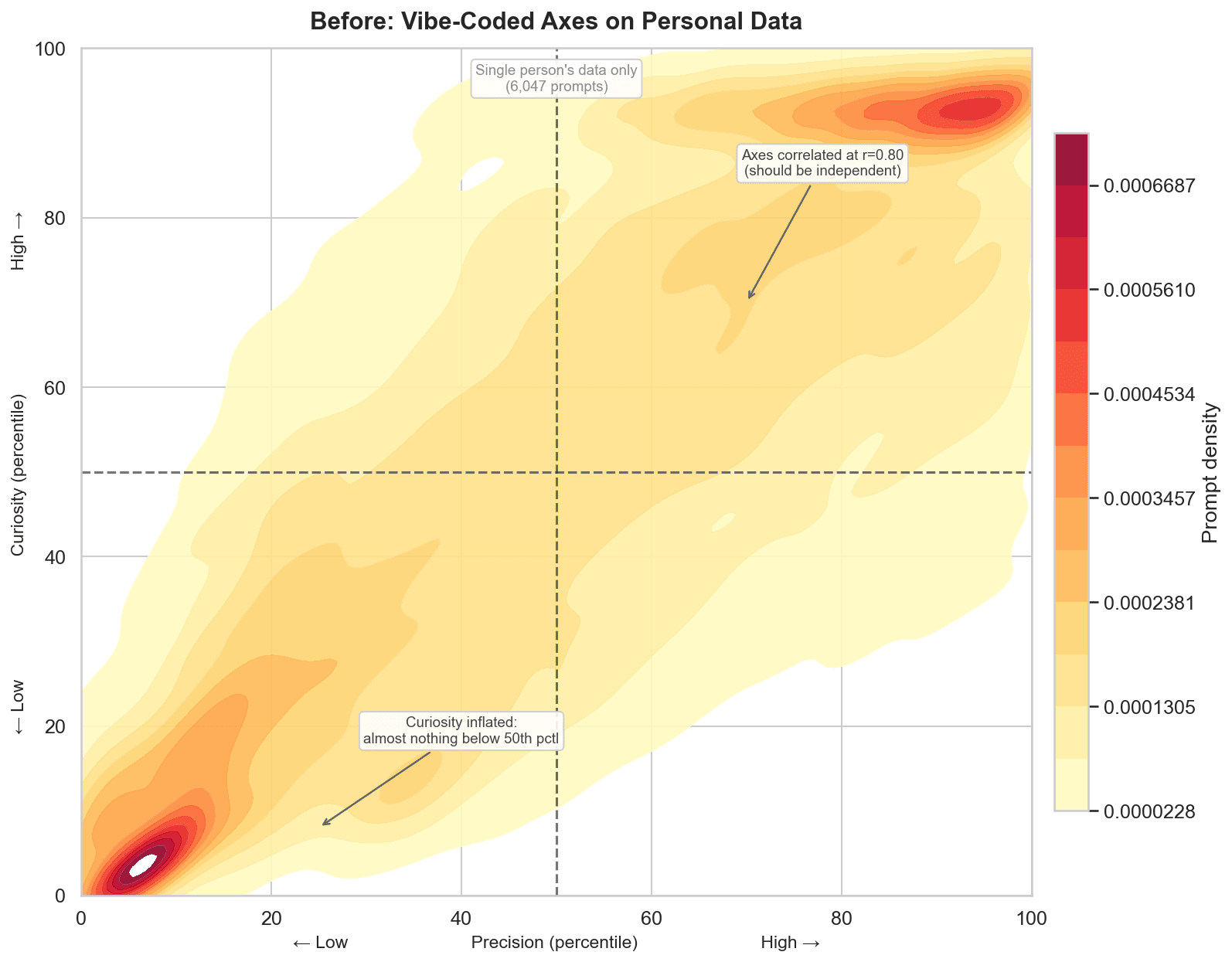
But the finding that really stung was when I ran it on my “cleaned” real data, the correlations between the four “independent” axes jumped to 0.80. This was much worse, and expected because now they truly reflected only one person’s prompting style. And they were all measuring the same thing: how long your prompt is. I had four labels, but essentially based on one dimension.
I spent a whole week on just the validation. The AI had built the system in twenty minutes. This asymmetry of effort is the whole story of vibe coding.
The rebuild
I started over. This time applying the correct data science process similar to how I would do it (myself or direct my team) on a real-world project.
Research: I read some real literature on how developers interact with AI coding tools.
Barke et al. found developers switch between acceleration mode (I know what I want, just do it) and exploration mode (let me understand this first)
Ross et al. showed task type predicts interaction patterns
At least this was a starting point on referencing some documented behavioral differences in how people code
Design: From the research, two dimensions kept emerging: how much you specify (brief vs. detailed) and how you frame the interaction (directive vs. collaborative). Taking those two, I built transparent, countable markers for each:
Word count and constraints for detail level
“Can you” vs. “just do it” for communication style
Yes this was back to regex, but I think it was more reliable than a blanket application of an embeddings model to understand what a prompt “means”.
Data: I pulled in 15,000 coding prompts from public research datasets so I wasn’t just validating against my own data anymore. Total: 21,000 prompts from diverse users across multiple platforms.
Results: Two axes with a correlation of r=0.20. The old system’s axes correlated at r=0.80 — sharing 64% of their variance, basically measuring the same thing. The new axes share 4%. Pretty different system.
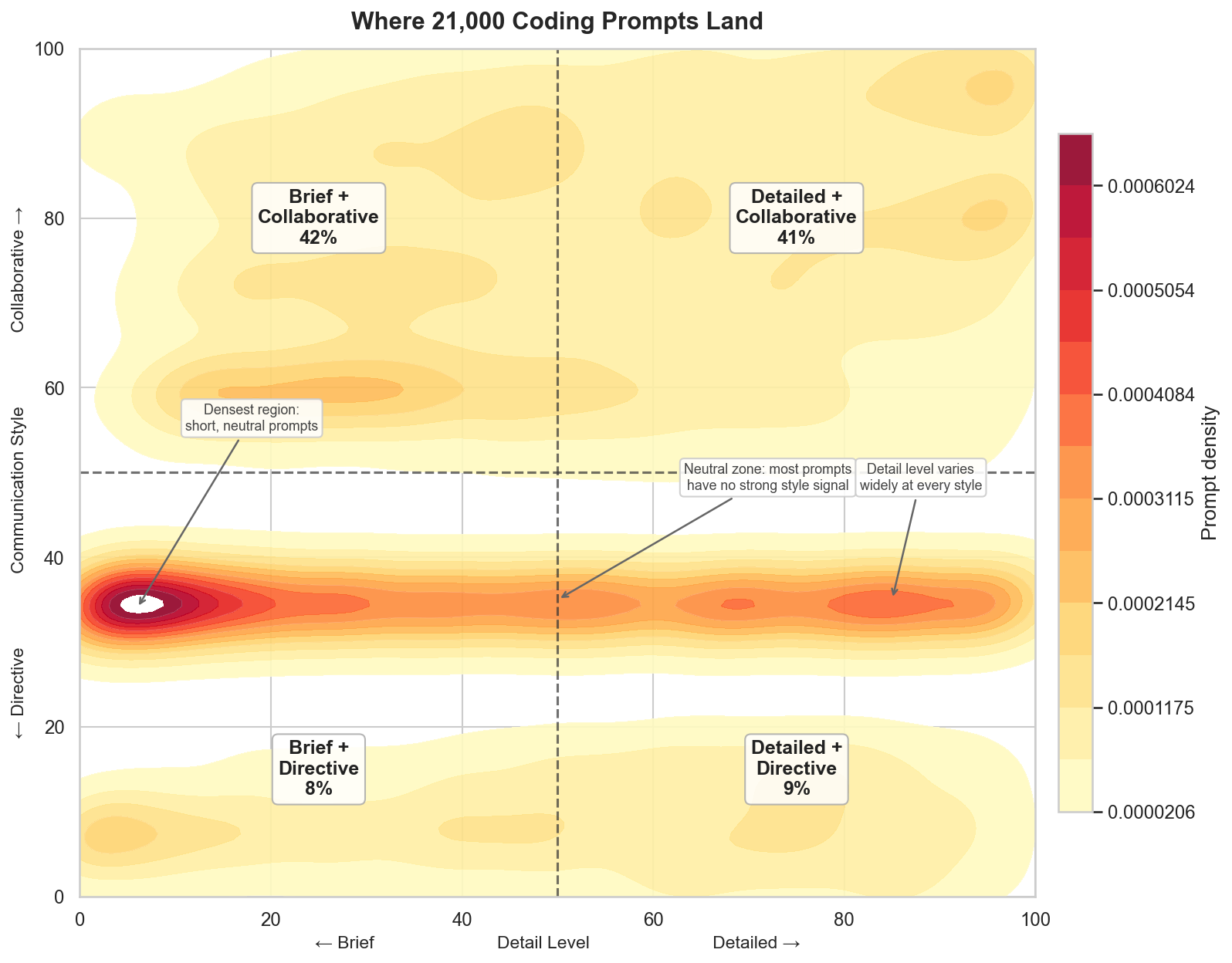
The breakdown: 42% Brief+Collaborative, 41% Detailed+Collaborative, 9% Detailed+Directive, 8% Brief+Directive.
Interesting finding was that most people are polite to their AI coding tools, even when they're just typing "do it." The directive quadrants are small but real, and they light up the hottest on the density plot because those prompts all sound the same ("yes", "go ahead", "just do it") while collaborative prompts are wildly diverse. This is the reality of the world, real behaviors are always skewed in some direction either due to some sort of internal or external bias.
Honest status check
I’m not going to pretend that the de-vibing is done correctly. This is after all the domain of linguistic and behavioral analysis, and I’m no domain expert. I’d rather have folks with real expertise advise me on which directions to take and what methods to apply. This is one of my joys of being able to work with PhDs and other experts in different domains professionally. The “PhD level” AI agent is total BS, and easy to market to those who’ve never worked with real talent.
What’s better:
The axes are independent (4% shared variance now vs 64% earlier)
The features are transparent — no black boxes
The data is broader (21K prompts, not just mine) and cleaner (39 exclusion rules filtering out the noise in the chat logs)
What’s still not fully done:
Since shipping the new system, I labeled 1,000 prompts and measured the Vibe and Politeness classifiers at 62% and 76% accuracy — up from 38% and 42% baselines. That’s some real progress
The persona quadrant assignment uses threshold rules on the two axes, so it’s validated by the distribution spread rather than a held-out test set
The external datasets still include some non-coding prompts that slipped through filters
And 83% of prompts landing in the collaborative half — that might be reality, or it might be an artifact of the data I’m training on
The de-vibing moved the system from “confidently broken” to “probably better, but I haven’t fully proved it yet.” But it’s far more trustworthy than what I had before.
Final Lesson
I used agentic coding tools to build the replacement app too. Every step — the exclusion rules, the markers, the axis construction — was AI-assisted (except for all the SQL I had to write to point the AI in the right direction). The de-vibing itself was vibe-coded, in a sense, but the level of mental effort on my end to really dig into the details was significant. Just like a real project.
The difference was whether I reviewed the data and made all the critical methodology decisions. The old system was completely based on vibes. The new system was fully validated, grounded in published research, and now I (the builder / data scientist) know enough to fully explain all the details and trade-offs.
The lesson I learned here is that you don’t need to stop using AI to get high quality results. It just isn’t possible to completely offload all tasks to agentic coding tools and expect the same results as if you’d worked on this project yourself.
Now this is the real paradox — could I have built all of this myself? Yes. But it would have taken me months. And because I knew it would have taken me months, I would never have started in the first place. AI tools are incredible at helping you manifest ideas into something real, but as prototypes, not fully built products.
LLMs are autocomplete on steroids. Incredibly useful autocomplete. But autocomplete doesn’t do the critical thinking for you. That’s still your job.
Try it yourself
If you use any AI coding assistant — Claude Code, Codex, Copilot Chat, Cursor, LM Studio, Pi, or OpenCode — you can run the v2 of How I Prompt on your own conversations right now. One npx command, and nothing to install beyond Node.js:
npx @eeshans/howipromptIt syncs your local conversation logs, runs the full pipeline on your machine (scoring, persona classification, trends), and opens a dashboard in your browser. You get an analytics overview and a scroll-through “Wrapped” experience with your persona, vibe coder index, politeness score, activity heatmaps, and more.
Everything stays local. No prompt data leaves your machine. The pipeline runs entirely on-device using lightweight feature-based scoring and a SQLite database file.
If you run this, please share your persona and dashboard screenshots!
You can see a demo with my data here: https://howiprompt.eeshans.com/
Please don’t judge my activity levels or heat-map. This is my passion project after all.
This is Part 1 of the How I Prompt de-vibing series. In Part 2, I'll open up the notebooks and walk through the full scientific process — the statistics, the feature engineering, the exact methodology — for readers who want the technical deep dive. If you've ever wondered how to properly validate an ML system you (or your AI) built, that one's for you.